

Pi Cubed :
Dans le domaine en pleine évolution de la vision par ordinateur, une nouvelle approche nommée π³ (Pi Cubed) a émergé, redéfinissant la manière dont les réseaux neuronaux reconstruisent la géométrie visuelle. Développée par une équipe de chercheurs, π³ propose une méthode innovante qui élimine le besoin d’une vue de référence fixe, une limitation courante dans les méthodes traditionnelles et modernes.
Qu’est-ce que π³ ou (Pi Cubed)?
π³ est un réseau neuronal de type feed-forward conçu pour la reconstruction géométrique à partir d’images, qu’il s’agisse d’une seule image, de séquences vidéo ou d’ensembles d’images non ordonnées. Contrairement aux approches classiques comme Structure-from-Motion (SfM) ou Multi-View Stereo (MVS), qui s’appuient sur une vue de référence fixe pour établir un système de coordonnées global, π³ adopte une architecture entièrement équivariante aux permutations. Cela signifie que l’ordre des images en entrée n’influence pas les résultats, ce qui constitue une avancée significative pour la robustesse et l’évolutivité des modèles de vision 3D.
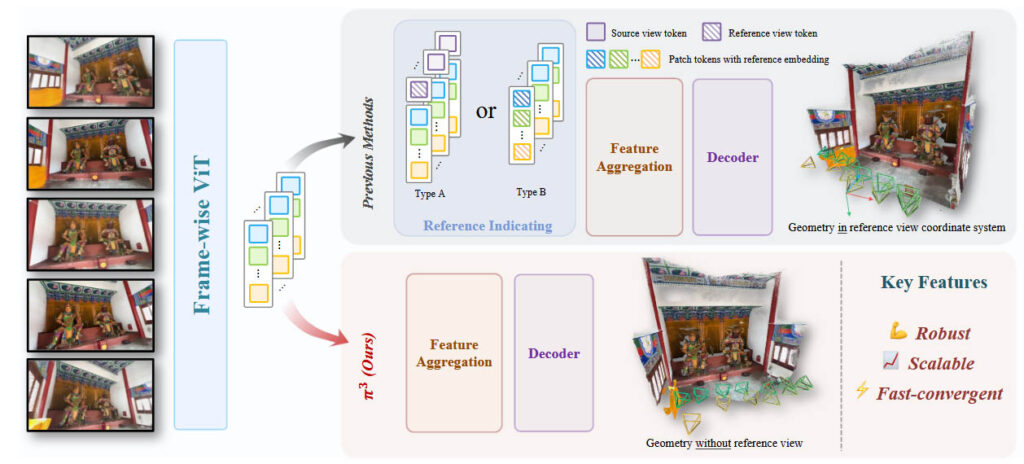
Fonctionnement de π³
Le fonctionnement de π³ repose sur plusieurs principes clés :
- Équivariance aux Permutations : π³ élimine le besoin d’une vue de référence en prédisant des poses de caméra invariantes par affinité et des cartes de points locales invariantes à l’échelle, toutes relatives au système de coordonnées de chaque image. Cela garantit une cohérence des résultats, peu importe l’ordre des entrées.
- Architecture Transformeur : Le modèle utilise une architecture transformeur avec une alternance d’auto-attention par vue et globale, similaire à celle utilisée dans VGGT, mais sans les composants dépendants de l’ordre, comme les embeddings positionnels basés sur l’index des images.
- Prédictions Relatives : π³ prédit des poses de caméra et des cartes de points pour chaque image sans nécessiter un cadre de référence global, rendant le modèle insensible aux choix arbitraires de vue initiale.
- Entraînement en Deux Étapes : Le modèle est entraîné en deux phases : une première à basse résolution (224×224 pixels) et une seconde à des résolutions variées, avec une stratégie de batch dynamique. Les poids initiaux proviennent d’un modèle pré-entraîné (VGGT), avec l’encodeur gelé pendant l’entraînement.
Applications Pratiques
π³ excelle dans plusieurs tâches de vision par ordinateur, notamment :
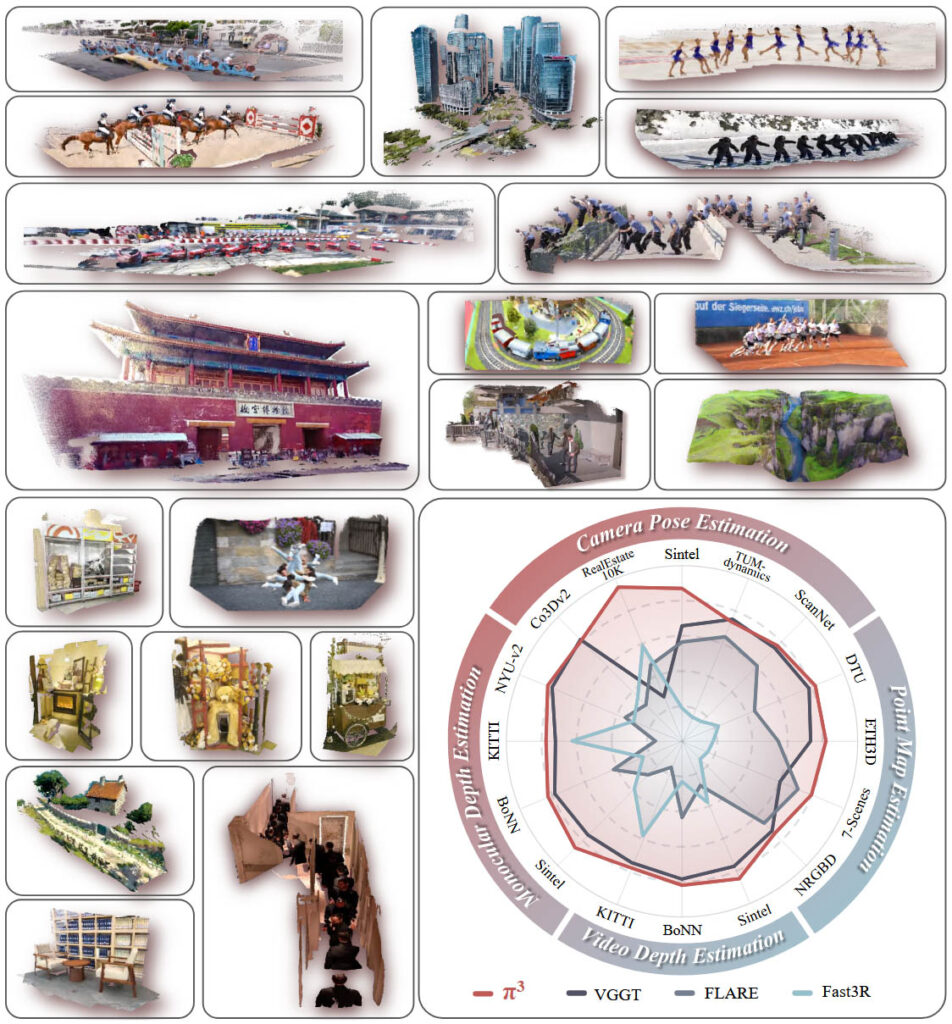
- Estimation de la Pose de Caméra : Sur des benchmarks comme RealEstate10K et Sintel, π³ réduit significativement l’erreur de translation et de rotation par rapport à des méthodes comme VGGT.
- Estimation de Profondeur Monoculaire et Vidéo : π³ surpasse les modèles comme MoGe et VGGT en termes d’erreur relative absolue, avec une efficacité impressionnante (57,4 FPS sur KITTI).
- Reconstruction de Cartes de Points Denses : Sur des ensembles comme DTU et ETH3D, π³ produit des reconstructions plus précises et cohérentes, même dans des scénarios à vues éparses.
Avantages de π³
En tant que reviewer, plusieurs aspects de π³ se démarquent comme particulièrement impressionnants :
- Robustesse à l’Ordre des Entrées : L’équivariance aux permutations élimine les biais liés au choix d’une vue de référence, un problème courant dans les approches traditionnelles. Les tests montrent une variance quasi nulle dans les métriques de reconstruction, même lorsque l’ordre des images varie.
- Évolutivité : π³ démontre une amélioration constante des performances avec l’augmentation de la taille du modèle, comme observé dans les tests avec des modèles Small (196,49M paramètres), Base (390,13M) et Large.
- Convergence Rapide : Le modèle converge plus rapidement que les baselines non équivariantes, réduisant le temps d’entraînement tout en maintenant une haute précision.
- Efficacité Computationnelle : Avec une vitesse d’inférence de 57,4 FPS sur KITTI, π³ surpasse des concurrents comme VGGT (43,2 FPS) et Dust3R (1,2 FPS), tout en étant plus léger.
- Polyvalence : π³ gère aussi bien les scènes statiques que dynamiques, ce qui le rend adapté à une large gamme d’applications, de la réalité augmentée à la navigation autonome.
Inconvénients et Limites
Malgré ses avancées, π³ présente certaines limites qu’il est important de souligner :
- Objets Transparents : Le modèle ne prend pas en compte les phénomènes complexes de transport de lumière, ce qui limite sa capacité à gérer des objets transparents ou réfléchissants.
- Détails Fins : Comparé aux approches basées sur la diffusion, π³ produit des reconstructions géométriques moins détaillées, ce qui peut être un frein pour des applications nécessitant une précision extrême.
- Artefacts de Grille : La génération de nuages de points repose sur un mécanisme d’upsampling simple (MLP avec pixel shuffling), qui peut introduire des artefacts en forme de grille, particulièrement dans les régions à forte incertitude.
- Dépendance aux Données d’Entraînement : Bien que π³ soit robuste, ses performances dépendent toujours de la qualité et de la diversité des données d’entraînement, notamment pour les scénarios en conditions réelles (« in-the-wild »).
Comparaison avec les Méthodes Existantes
Par rapport à des méthodes comme VGGT et Dust3R, π³ se distingue par son absence de dépendance à une vue de référence et sa robustesse à l’ordre des entrées. Les tests sur des datasets comme Sintel, KITTI, DTU et ETH3D montrent que π³ surpasse ces méthodes en termes de précision et d’efficacité, tout en maintenant une variance beaucoup plus faible dans les résultats. Par exemple, sur Sintel, π³ réduit l’erreur de translation de la pose de caméra de 0,16 (VGGT) à 0,074, et l’erreur relative absolue de profondeur vidéo de 0,29 à 0,23.

Conclusion
π³ représente une avancée majeure dans le domaine de la reconstruction géométrique visuelle. Son architecture équivariante aux permutations élimine un biais inductif fondamental, offrant une robustesse et une évolutivité inégalées. Bien que des limites subsistent, notamment pour les objets transparents et les détails fins, les performances de π³ sur des benchmarks variés et son efficacité computationnelle en font un outil prometteur pour des applications pratiques. Pour les chercheurs et les développeurs en vision par ordinateur, π³ ouvre la voie à des systèmes 3D plus stables et polyvalents.





